广告点击预测
通过历史购物数据预测用户看到某广告时的点击概率
Link: https://tianchi.aliyun.com/datalab/dataSet.htm?spm=5176.100073.888.26.278a33d8vhDWE7&id=19
题目描述
现在的人们习惯在网上买东西,而且经常看到购物网站为人们推荐各种各样的商品。有的时候,这些网站推荐的东西十分精准,我们会点击广告,仔细查看具体是什么商品;有的时候推荐的就有失偏颇,用户反而觉得这些广告令人生厌。
这也就是推荐广告问题,在该问题中,网站或者企业往往具有一定量的用户历史数据,并试图利用这些数据为用户推荐新的商品。具体推荐什么样的商品,才能吸引用户的注意力?推荐的商品用户会不会点击?这是推荐广告的核心问题,也是很多企业都在研究的问题。
在该项目中,提供了一段时间内的用户行为和广告信息,通过这些数据,请你预测部分推荐的广告,用户是否会点击。
小提示
先修技能
术语解释
- 推荐算法:推荐算法是计算机专业中的一种算法,通过一些数学算法,推测出用户可能喜欢的东西。目前常用的推荐算法分类包括:基于内容、基于协同、关联规则、基于效用、基于知识、组合推荐。
- 神经网络:人工神经网络(Artificial Neural Networks,简写为ANNs)也简称为神经网络(NNs)或称作连接模型(Connection Model),它是一种模仿动物神经网络行为特征,进行分布式并行信息处理的算法数学模型。这种网络依靠系统的复杂程度,通过调整内部大量节点之间相互连接的关系,从而达到处理信息的目的。
- 协同过滤:协同过滤简单来说是利用某兴趣相投、拥有共同经验之群体的喜好来推荐用户感兴趣的信息,个人通过合作的机制给予信息相当程度的回应(如评分)并记录下来以达到过滤的目的进而帮助别人筛选信息,回应不一定局限于特别感兴趣的,特别不感兴趣信息的纪录也相当重要。
- kNN:邻近算法,或者说K最近邻(kNN,k-NearestNeighbor)分类算法是数据挖掘分类技术中最简单的方法之一。所谓K最近邻,就是k个最近的邻居的意思,说的是每个样本都可以用它最接近的k个邻居来代表。
- AUC:AUC(Area Under Curve)被定义为ROC曲线下的面积,显然这个面积的数值不会大于1。又由于ROC曲线一般都处于y=x这条直线的上方,所以AUC的取值范围在0.5和1之间。使用AUC值作为评价标准是因为很多时候ROC曲线并不能清晰的说明哪个分类器的效果更好,而作为一个数值,对应AUC更大的分类器效果更好。
输入格式
数据包括了train、test、ad_feature、user_profile、raw_behavior_log四张表。
1、训练数据train:
包含了260多万条广告出现时用户的点击情况。6条字段说明如下:
- user_id:用户ID;
- time_stamp:时间戳;
- adgroup_id:广告ID;
- pid:资源号;
- nonclk:为1代表没有点击;为0代表点击;
- clk:与nonclk相反,为0代表没有点击;为1代表点击;
2、测试数据test:
包含了3万条广告出现时的情况,和train类似,只不过没有nonclk和clk字段,clk字段即为你要预测的内容。test具体的4条字段说明如下:
- user_id:用户ID;
- time_stamp:时间戳;
- adgroup_id:广告ID;
- pid:资源号;
3、广告信息ad_feature
包含了相关的广告的信息。6条字段说明如下:
- adgroup_id:广告ID;
- cate_id:对应的商品类目ID;
- campaign_id:广告计划ID;
- customer_id:广告主ID;
- brand:品牌ID;
- price:商品价格
其中一个广告ID对应一个商品,一个商品只属于一个类目,一个商品也只属于一个品牌。
4、用户信息user_profile
包含了相关的用户的信息。9条字段说明如下:
- userid:用户ID;
- cms_segid:微群ID;
- cms_group_id:微群组ID;
- final_gender_code:性别1:男,2:女;
- age_level:年龄层次;
- pvalue_level:消费档次,1:低档,2:中档,3:高档;
- shopping_level:购物深度,1:浅层用户,2:中度用户,3:深度用户
- occupation:是否是大学生,1:是,0:否
- new_user_class_level:城市层级
5、用户的行为日志behavior_log 本数据集涵盖了raw_sample中全部用户一段时间内的购物行为。5条字段说明如下:
- user:用户ID;
- time_stamp:时间戳;
btag:行为, 包括以下四种:
- pv:浏览
- cart:加入购物车
- fav:喜欢、收藏
- buy:购买
cate:商品类目;
brand:品牌词;
这里会有很多重复的记录(以user + time_stamp为key);这是因为不同类型的行为数据是不同部门记录的,在打包到一起的时候,会有小的偏差(即两个一样的time_stamp实际上是差异比较小的两个时间)。
输出格式
直接按test集顺序输出对应的点击概率,不需要加任何表头和id,详见sample_submission.csv。
0.05
0.06
0.07
(29997 more lines)
评价
使用 AUC 作为最后评判标准。
下面简单介绍AUC,介绍AUC之前先介绍ROC:
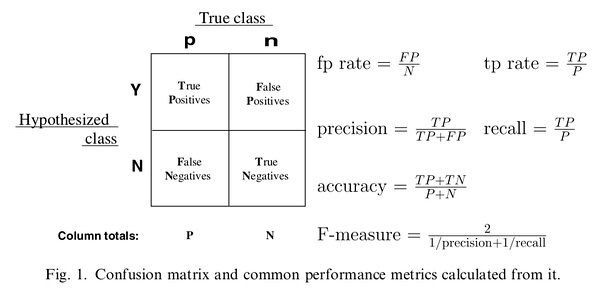
正如我们在这个ROC曲线的示例图中看到的那样,ROC曲线的横坐标为false positive rate(FPR),纵坐标为true positive rate(TPR)。下图中详细说明了FPR和TPR是如何定义的。
接下来我们考虑ROC曲线图中的四个点和一条线。第一个点,(0,1),即FPR=0, TPR=1,这意味着FN(false negative)=0,并且FP(false positive)=0。这是一个完美的分类器,它将所有的样本都正确分类。第二个点,(1,0),即FPR=1,TPR=0,类似地分析可以发现这是一个最糟糕的分类器,因为它成功避开了所有的正确答案。第三个点,(0,0),即FPR=TPR=0,即FP(false positive)=TP(true positive)=0,可以发现该分类器预测所有的样本都为负样本(negative)。类似的,第四个点(1,1),分类器实际上预测所有的样本都为正样本。经过以上的分析,我们可以断言,ROC曲线越接近左上角,该分类器的性能越好。
AUC(Area Under Curve)被定义为ROC曲线下的面积,显然这个面积的数值不会大于1。又由于ROC曲线一般都处于y=x这条直线的上方,所以AUC的取值范围在0.5和1之间。使用AUC值作为评价标准是因为很多时候ROC曲线并不能清晰的说明哪个分类器的效果更好,而作为一个数值,对应AUC更大的分类器效果更好。
既然已经这么多评价标准,为什么还要使用ROC和AUC呢?因为ROC曲线有个很好的特性:当测试集中的正负样本的分布变化的时候,ROC曲线能够保持不变。在实际的数据集中经常会出现类不平衡(class imbalance)现象,即负样本比正样本多很多(或者相反),而且测试数据中的正负样本的分布也可能随着时间变化。这时使用AUC评价指标就会更加准确。
数据
- 数据较大,全部放到百度云,correct_submission.csv是正确答案,其他全给用户。
- 链接:https://pan.baidu.com/s/1ggDTN6j 密码:75zr
测评配置环境
python
pip install -U numpy
pip install pandas
pip install -U scikit-learn
测评代码
from sklearn.metrics import roc_auc_score
import pandas as pd
y_test = pd.read_csv(data_dir + "correct_submission.csv") # 正确答案
y_pred = pd.read_csv(data_dir + "prediction_test.csv") # 用户预测的答案
auc = roc_auc_score(y_test, y_pred)
# 越大越好,最大为1,最小为0.