Bag of Words Meets Bags of Popcorn
通过电影评论的文字信息中识别出评论者的态度
Link: https://www.kaggle.com/c/word2vec-nlp-tutorial/
题目描述
对电影的评论文字的处理是自然语言处理中情感分析方向的一个很好的例子。人们的语言经常具有不确定性,有的甚至包括了讽刺、反语等等。如何识别出评论者的态度是一大难点。
在这道题中,给出电影评论,要求识别出这条评论是积极的还是消极的。
对于文字处理的方法一般为:第一步从自然语言中提取出特征,第二步对特征进行适当的分类器训练。(在分类器的选择中建议采用神经网络等比较强的分类器。)
第一步特征提取可以尝试采用Google的Word2Vec方法,Word2Vec试图理解单词之间的含义和语义关系。它的原理类似于循环神经网络,但计算效率更高。此外也可以使用TF-IDF、词袋法等等。
小提示
- 本题是一道自然语言处理当中的情感分析。
- 可以先从句子当中提取出特征,方法如Word2Vec,TF-IDF,词袋法等等。
- 提取出特征后,可以采用朴素贝叶斯,朴素贝叶斯在文本处理当中有比较好的表现效果。也可以采用SVM、循环神经网络等较强的分类器。
- 通过该分类器,给出一个概率值,这个值不需要再进一步处理为0-1二值,因为这里采用AUC进行评价。
先修技能
解释术语
循环神经网络:多层反馈RNN(Recurrent neural Network、循环神经网络)神经网络是一种节点定向连接成环的人工神经网络。这种网络的内部状态可以展示动态时序行为。不同于前馈神经网络的是,RNN可以利用它内部的记忆来处理任意时序的输入序列,这让它可以更容易处理如不分段的手写识别、语音识别等。
朴素贝叶斯:朴素贝叶斯法是基于贝叶斯定理与特征条件独立假设的分类方法。最为广泛的两种分类模型是决策树模型(Decision Tree Model)和朴素贝叶斯模型(Naive Bayesian Model,NBM)。和决策树模型相比,朴素贝叶斯分类器(Naive Bayes Classifier,或 NBC)发源于古典数学理论,有着坚实的数学基础,以及稳定的分类效率。同时,NBC模型所需估计的参数很少,对缺失数据不太敏感,算法也比较简单。理论上,NBC模型与其他分类方法相比具有最小的误差率。但是实际上并非总是如此,这是因为NBC模型假设属性之间相互独立,这个假设在实际应用中往往是不成立的,这给NBC模型的正确分类带来了一定影响。
TF-IDF:TF-IDF是一种统计方法,用以评估一字词对于一个文件集或一个语料库中的其中一份文件的重要程度。字词的重要性随着它在文件中出现的次数成正比增加,但同时会随着它在语料库中出现的频率成反比下降。TF-IDF加权的各种形式常被搜索引擎应用,作为文件与用户查询之间相关程度的度量或评级。除了TF-IDF以外,因特网上的搜索引擎还会使用基于链接分析的评级方法,以确定文件在搜寻结果中出现的顺序。
AUC:AUC(Area Under Curve)被定义为ROC曲线下的面积,显然这个面积的数值不会大于1。又由于ROC曲线一般都处于y=x这条直线的上方,所以AUC的取值范围在0.5和1之间。使用AUC值作为评价标准是因为很多时候ROC曲线并不能清晰的说明哪个分类器的效果更好,而作为一个数值,对应AUC更大的分类器效果更好。
word2vec:word2vec可以在百万数量级的词典和上亿的数据集上进行高效地训练,该工具得到的训练结果——词向量(word embedding),可以很好地度量词与词之间的相似性。随着深度学习(Deep Learning)在自然语言处理中应用的普及,很多人误以为word2vec是一种深度学习算法。其实word2vec算法的背后是一个浅层神经网络。另外需要强调的一点是,word2vec是一个计算word vector的开源工具。当我们在说word2vec算法或模型的时候,其实指的是其背后用于计算word vector的CBoW模型和Skip-gram模型。很多人以为word2vec指的是一个算法或模型,这也是一种谬误。
输入格式
labeledTrainData.tsv是有Label的训练集,包含20000行评论数据,包括评论id、评论文本、情感(0代表消极,1代表积极)。testData.tsv是一个无Label的测试集,包含5000行评论数据,包括评论id、评论文本,没有对应情感。unlabeledTrainData.tsv是额外的50000行无Label数据,包括评论id和评论文本。可用来进行文本特征提取或半监督学习。sampleSubmission.csv是一个提交格式的样例。
输出格式
您的提交csv文件应包含行名,并采用以下格式:对于测试集中的每条评论,输出一行,其中包含评论id和对应预测的结果(注意,可以提交[0, 1]以内的任意数值,表示预测为正例的score,最终会采用AUC进行评价)。如下所示:
id,sentiment
3862_4,0
674_10,1
8828_10,0
(4997 more lines)
评价
使用 AUC 作为最后评判标准。
下面简单介绍AUC,介绍AUC之前先介绍ROC:
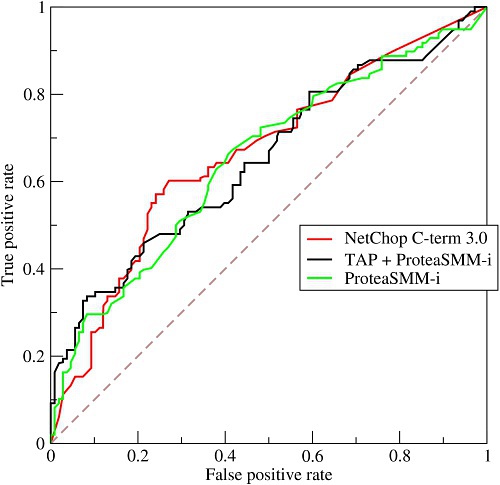
正如我们在这个ROC曲线的示例图中看到的那样,ROC曲线的横坐标为false positive rate(FPR),纵坐标为true positive rate(TPR)。下图中详细说明了FPR和TPR是如何定义的。
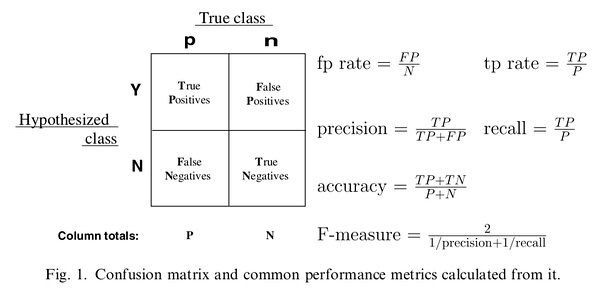
接下来我们考虑ROC曲线图中的四个点和一条线。第一个点,(0,1),即FPR=0, TPR=1,这意味着FN(false negative)=0,并且FP(false positive)=0。这是一个完美的分类器,它将所有的样本都正确分类。第二个点,(1,0),即FPR=1,TPR=0,类似地分析可以发现这是一个最糟糕的分类器,因为它成功避开了所有的正确答案。第三个点,(0,0),即FPR=TPR=0,即FP(false positive)=TP(true positive)=0,可以发现该分类器预测所有的样本都为负样本(negative)。类似的,第四个点(1,1),分类器实际上预测所有的样本都为正样本。经过以上的分析,我们可以断言,ROC曲线越接近左上角,该分类器的性能越好。
AUC(Area Under Curve)被定义为ROC曲线下的面积,显然这个面积的数值不会大于1。又由于ROC曲线一般都处于y=x这条直线的上方,所以AUC的取值范围在0.5和1之间。使用AUC值作为评价标准是因为很多时候ROC曲线并不能清晰的说明哪个分类器的效果更好,而作为一个数值,对应AUC更大的分类器效果更好。
既然已经这么多评价标准,为什么还要使用ROC和AUC呢?因为ROC曲线有个很好的特性:当测试集中的正负样本的分布变化的时候,ROC曲线能够保持不变。在实际的数据集中经常会出现类不平衡(class imbalance)现象,即负样本比正样本多很多(或者相反),而且测试数据中的正负样本的分布也可能随着时间变化。这时使用AUC评价指标就会更加准确。
代码与数据
- labeledTrainData: https://github.com/GilYexiao/DataSet/raw/master/BagOfWords/labeledTrainData.tsv
- testData: https://github.com/GilYexiao/DataSet/raw/master/BagOfWords/testData.tsv
- unlabeledTrainData: https://www.kaggle.com/c/word2vec-nlp-tutorial/download/unlabeledTrainData.tsv.zip
- sampleSubmission: https://github.com/GilYexiao/DataSet/raw/master/BagOfWords/sampleSubmission.csv
- correct_submission: https://github.com/GilYexiao/DataSet/raw/master/BagOfWords/correct_submission.csv
完整代码
- MultinomialNB version: https://www.kaggle.com/ayanmaity/bag-of-words-meets-popcorns
- 官方教程:https://www.kaggle.com/c/word2vec-nlp-tutorial
测评配置环境
python
pip install -U numpy
pip install pandas
pip install -U scikit-learn
测评代码
from sklearn.metrics import roc_auc_score
import pandas as pd
y_test = pd.read_csv(data_dir + "correct_submission.csv") # 正确答案
y_pred = pd.read_csv(data_dir + "prediction_test.csv") # 用户预测的答案
auc = roc_auc_score(y_test['sentiment'],y_pred['sentiment'])